 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multilingual Personalized Descriptions of Museum Exhibits - The M-PIRO Project
Oct 29, 2001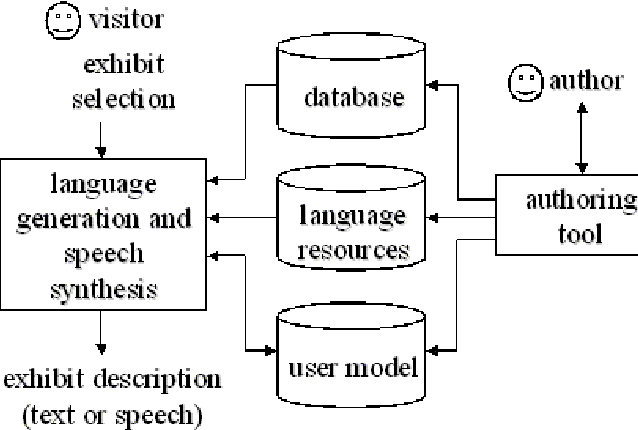
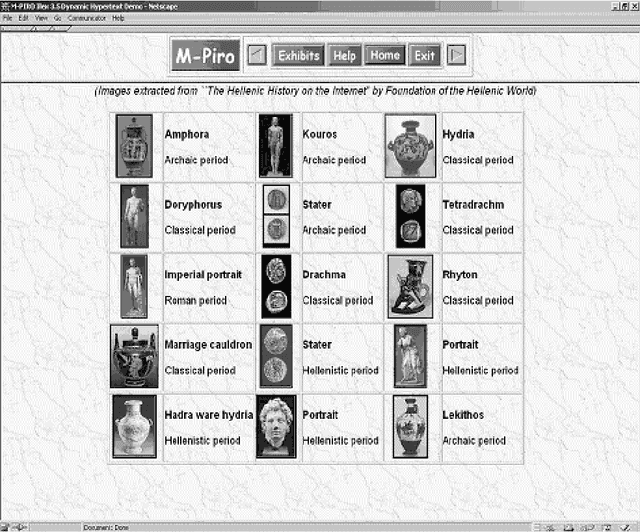
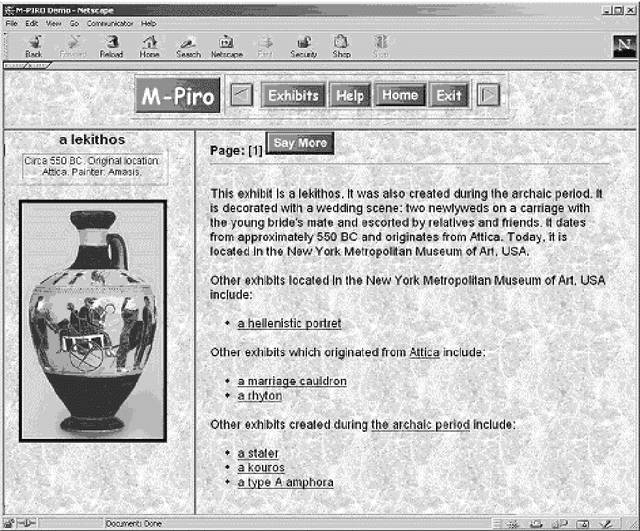
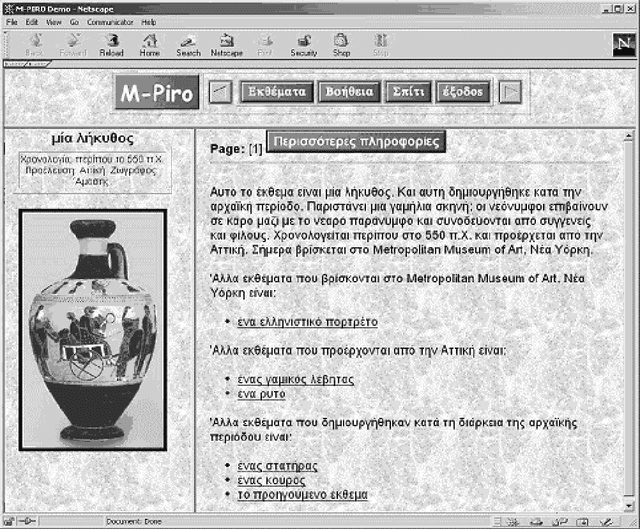
This paper provides an overall presentation of the M-PIRO project. M-PIRO is developing technology that will allow museums to generate automatically textual or spoken descriptions of exhibits for collections available over the Web or in virtual reality environments. The descriptions are generated in several languages from information in a language-independent database and small fragments of text, and they can be tailored according to the backgrounds of the users, their ages, and their previous interaction with the system. An authoring tool allows museum curators to update the system's database and to control the language and content of the resulting descriptions. Although the project is still in progress, a Web-based demonstrator that supports English, Greek and Italian is already available, and it is used throughout the paper to highlight the capabilities of the emerging technology.
On aligning trees
Jul 25, 1997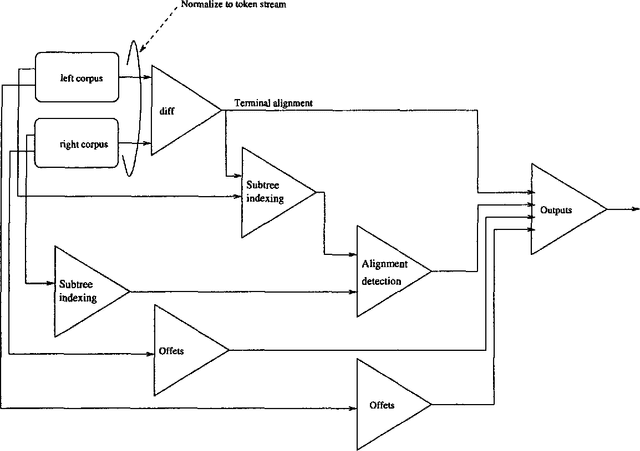
The increasing availability of corpora annotated for linguistic structure prompts the question: if we have the same texts, annotated for phrase structure under two different schemes, to what extent do the annotations agree on structuring within the text? We suggest the term tree alignment to indicate the situation where two markup schemes choose to bracket off the same text elements. We propose a general method for determining agreement between two analyses. We then describe an efficient implementation, which is also modular in that the core of the implementation can be reused regardless of the format of markup used in the corpora. The output of the implementation on the Susanne and Penn treebank corpora is discussed.